Image-to-Text Synthesizer: Comparing Diffusion, CNNs, and GANs
Image-to-text conversion has become increasily popular—for answering questions about images and extracting specific data that can be transformative in fields like medicine and education.
This project delves into three fundamental deep learning models for image-text: Convolutional Neural Networks (CNNs), Generative Adversarial Networks (GANs), and Diffusion Models (integrated with Vision Transformers and GPT-2).
Dataset Note
For this project, we used the well-known CIFAR-10 dataset, which comprises 60,000 32x32 color images across 10 classes (airplanes, cars, birds, cats, deer, dogs, frogs, horses, ships, and trucks).
Although the low resolution limits fine-grained detail extraction, CIFAR-10 was chosen for its simplicity , fast training and its ability to test model robustness under low hardware capabilities.

CNNs: The Backbone of Image Classification
Convolutional Neural Networks represent the earliest deep learning approach for image recognition.
How CNNs Work
- Convolution Layer: Filters (or kernels) slide over the image, computing dot products on local regions to create feature maps. This process captures essential features like edges, textures, and shapes, while weight sharing reduces the number of trainable parameters.
- Activation Layer: A non-linear activation function, such as ReLU, is applied to introduce non-linearity, allowing the network to model complex relationships.
- Pooling Layer: Pooling (using max or average pooling) reduces spatial dimensions, decreases computational complexity, and provides translation invariance.
After passing through several convolution and pooling layers, the resulting feature maps are flattened and fed into fully connected layers that perform the final classification or feature extraction.
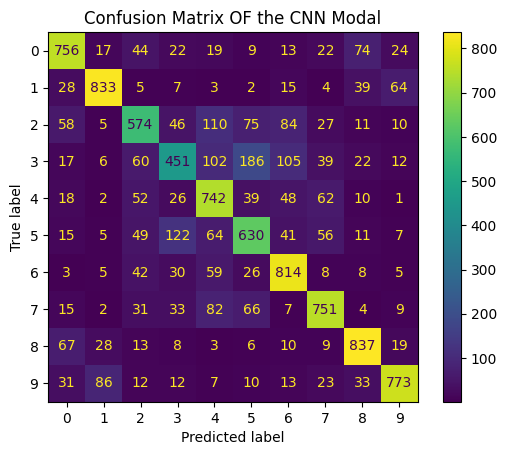

Even with a low training size (I trained around 10 epochs on CIFAR-10), the confusion matrix showed high performance in image classification, i.e Approximate 65% on average for all classes.
However certain classes (e.g., airplanes and cars) were accurately recognized, while others (like birds, cats, and deer) lagged behind as shown in the bar chart per label performance.
GANs: Generative Adversarial Networks
Generative Adversarial Networks (GANs) are a powerful deep learning framework for creating realistic images by utilizing two competing neural networks: a generator and a discriminator.
The generator starts by producing images from random noise, while the discriminator assesses whether an image is real (from actual data) or fake (created by the generator).
As training progresses, the generator refines its ability to mimic real images, while the discriminator continuously improves at distinguishing real from fake.
How GANs Work
GANs operate with two distinct but interlinked neural networks:
- Generator: Starting from a random noise vector, the generator uses transposed convolutions, batch normalization, and activations to create synthetic images designed to resemble real ones.
- Discriminator: Structured similarly to a CNN, the discriminator evaluates both the real images from the dataset and the synthetic images, distinguishing between the two.
Training is performed as a minimax game: the discriminator improves its ability to differentiate real from fake images, while the generator simultaneously learns to produce images that can fool the discriminator.
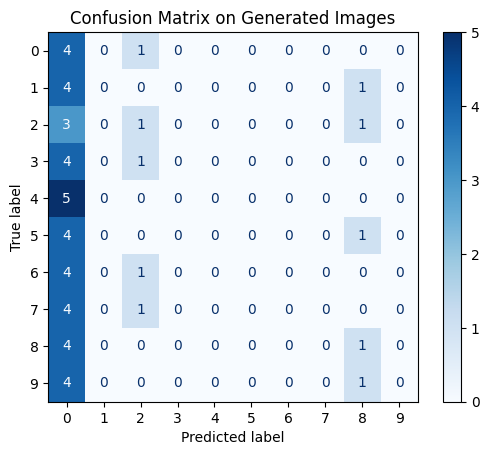
GANs are commonly used to generate realistic images from noisy data , though their training can be challenging due to issues like large training samples and the need to balance between the generator and discriminator losses.
Training GANs proved to be particularly challenging as shown in the images above. While they are generally expected to surpass CNNs in performance, this particular instance the GAN underperform due to limited training size and limited hardware
capacity. Looking at the confusion matrix that is trained on three set of image labels as shown, the results for image labeling apear to be random. This shows that the GAN requires additional training for more effective results.
GANs are designed to work with continuous data (like images) where gradients can be smoothly propagated.
Text generation, however, involves discrete tokens (words) and sequences, which makes it difficult to propagate gradients through the generator and discriminator.
Diffusion Models
Diffusion models, often famed for creating visually stunning AI-generated art, have now expanded their utility into text extraction and recognition. By gradually adding noise to an image and learning to reverse this process, they effectively reconstruct missing or blurry details—enabling richer textual synthesis.
Vision Transformers (ViTs) and GPT-2 Integration
In our application, we combined a Vision Transformer (ViT) with GPT-2 to create an advanced image-to-text synthesizer:
- Vision Transformer (ViT): The ViT partitions an image into patches, treating them as tokens and processing them with a transformer architecture to capture global context—a stark contrast to the primarily local feature extraction of CNNs.
- GPT-2: A pre-trained language model that, when provided with features extracted by ViT, generates detailed and contextually rich captions. This model produces descriptions that go well beyond simple labels, including details like the background context and object actions.

This diffusion-based approach not only provided superior accuracy on CIFAR-10, but also generated comprehensive descriptions that enriched the understanding of the scene—a significant advantage in fields like medical diagnostics and educational content creation.
Final thoughts
Convolutional Neural Networks (CNNs) are highly effective for image classification, delivering good results with efficient training.
CNNs are excellent at extracting local features and performing image classification, even with low-resolution images as shown within this project.
On the other hand, Generative Adversarial Networks (GANs) are a creative approach to image reasoning by generating realistic images. They are ideal for handling noisy inputs,
but require powerful tuning and
training and are not well-suited for image-to-text synthesis.
One of the biggest challenges in training GANs is finding the right balance between the generator and discriminator to minimize overall loss,
which requires extensive training and careful parameter tuning.
To classify images into predefined labels, I employed a simple classifier to generate outputs conditioned on specific image labels. However, without sufficient training the
model could not perform very well.
The Diffusion Model (ViT + GPT-2) deliver the best context-rich textual descriptions, which are even more descriptive than the datasets labels.
A key recommendation is to integrate traditional CNN or GAN models with large language models (LLM) like GPT.
This hybrid approach may improve the efficiency of CNNs and GANs, and their contextual richness of image reasoning and understanding.



